Why SeqHub Search Finds Biology Other Tools Miss
A PI at a leading microbial biotechnology and metagenomics institute recently described using SeqHub to identify and characterize a previously unknown genome. This genome was central to a product the lab was actively developing. Based on what they learned in SeqHub, they ordered the constructs to test for improved production.
This isn't a fluke. It reflects three things about how SeqHub search works that are different from most protein search tools.
1. Search by functional similarity, not just sequence identity
Most sequence search starts with alignment. Tools like BLAST find sequences by directly comparing letters in a sequence; fast and well-understood, but limited to detecting similarity above a certain sequence identity threshold. Profile-based methods like HMMs (used in HHpred, eggNOG, and Pfam) go further by building statistical models from aligned sequence families, improving sensitivity for distant relatives. But both approaches are still fundamentally alignment-derived, which means they struggle with proteins that have diverged significantly in sequence while retaining similar function.
Structure-based search tools like Foldseek sidestep this by comparing 3D protein shapes rather than sequences, surfacing functional analogs with no detectable sequence similarity. This is a meaningful step forward, but requires predicted or experimental structures and still operates independently of genomic context.
SeqHub search is embedding-based. Sequences are encoded into vector representations by gLM2, our genomic language model trained on 3.1 trillion base pairs of metagenomic data. These embeddings capture functional and contextual relationships, including genomic neighborhood, not just sequence or structural similarity. So when two proteins share a fold or a similar genomic context but low sequence identity, SeqHub can still surface connections, without needing a structure as input.
This is why SeqHub can find hits that alignment and profile-based tools miss, particularly for hypothetical proteins and sequences from underrepresented taxa like Archaea and uncultivated microbes.
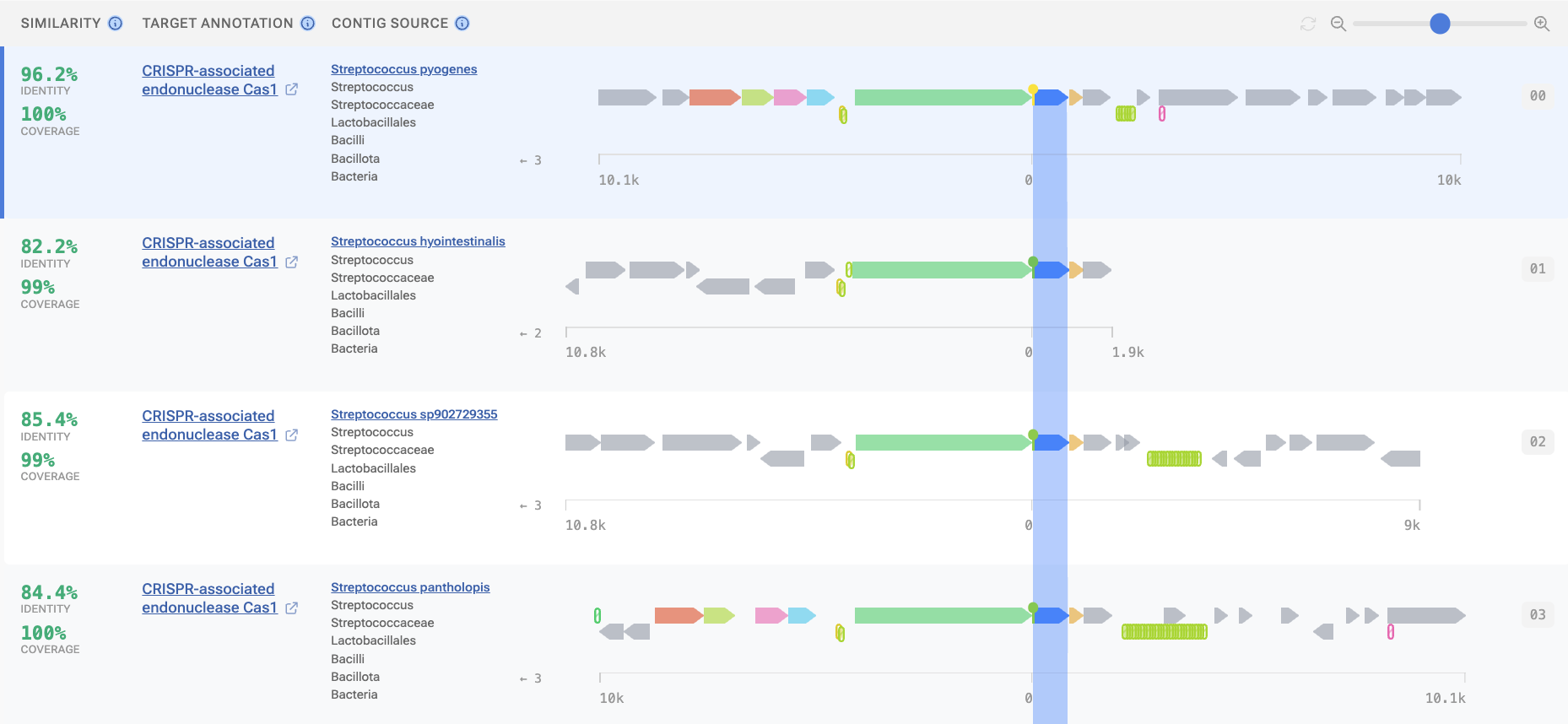
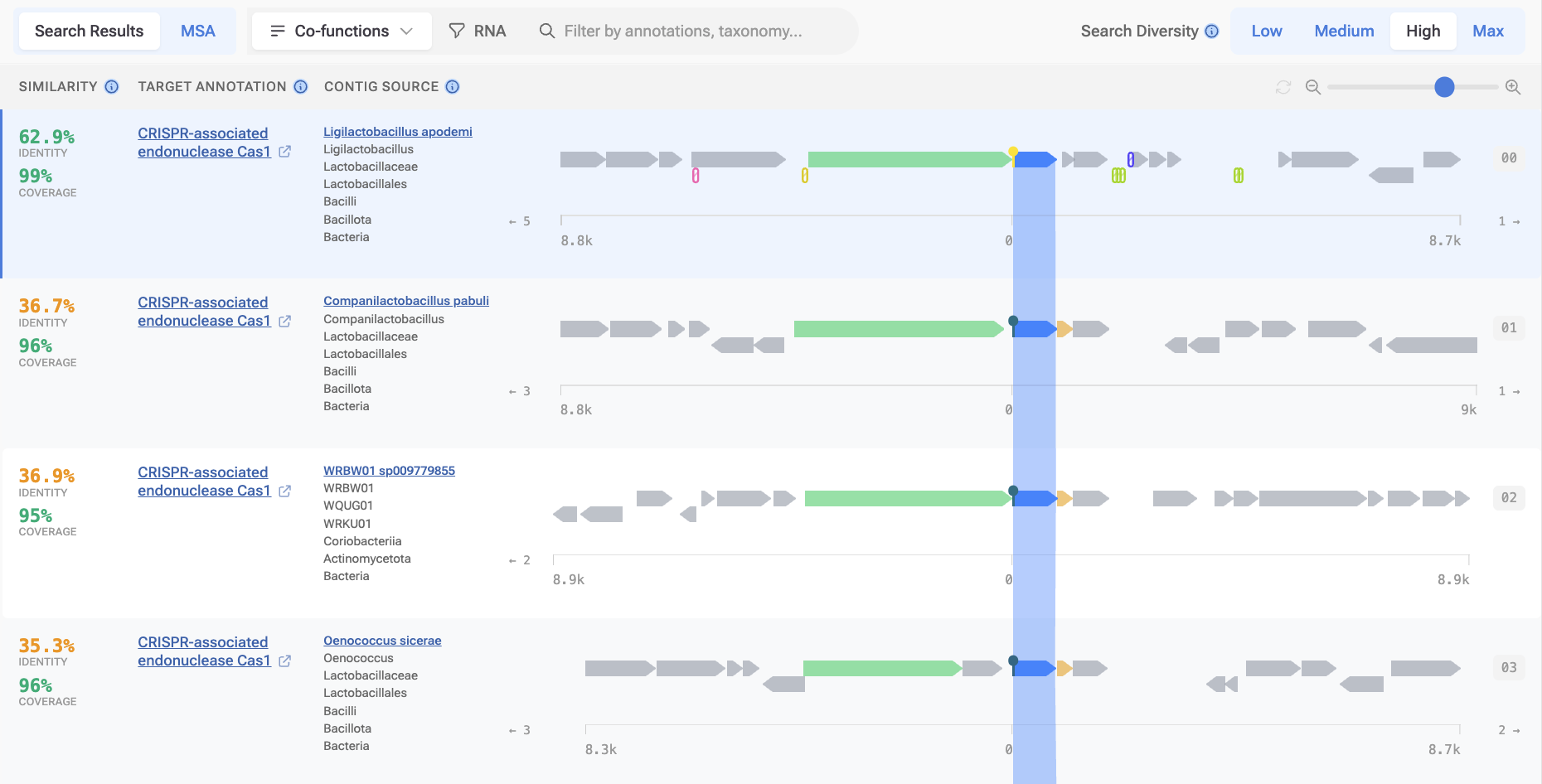
2. Control how diverse your results are
Most sequence search tools return results ranked by similarity, and SeqHub does too, but Diversity Search in SeqHub gives you an additional lever: adjust it to retrieve more distant homologs and surface sequences from across the tree of life that share functional similarity but wouldn't appear at the top of a standard search.
This is especially useful when you want to understand how conserved a protein or module is, find functional analogs in organisms you weren't already looking at, or explore whether a finding generalizes beyond your organism of focus.
3. Search at the system level, not just the sequence level
Single-protein search answers one question at a time. But many biological questions are relational: not "what is this protein?" but "where do these proteins appear together, and what does that imply?"
CoSearch lets you query multiple proteins simultaneously and find genomes where they co-occur. You can see their relative genomic proximity, compare neighborhood context across species, and identify conserved modules that wouldn't be visible from any single-protein search.
This is particularly useful for:
- Hypothetical proteins whose function is implied by their neighbors
- Biosynthetic gene clusters and operons
- Multi-protein defense or resistance systems like CRISPR-associated transposons
CoSearch also pairs naturally with FlashPPI, our proteome-wide protein-protein interaction prediction tool. If FlashPPI surfaces predicted interactions, CoSearch can help sense-check them by showing where those proteins actually co-occur across genomes.

These three capabilities — embedding-based retrieval, diversity control, and co-occurrence search — are the core of what makes SeqHub search different. But they're part of a broader platform where structure prediction, genomic neighborhood visualization, and literature are all surfaced alongside search results. The goal is to build context in one place rather than across five separate tools.
If you've hit a wall with BLAST or standard annotation pipelines, search SeqHub with the same sequence and see what comes back.
Search SeqHub →Frequently Asked Questions
What is the difference between BLAST and embedding-based protein search?
BLAST finds sequences by comparing residues directly — it breaks down when sequences have diverged significantly. Embedding-based search encodes functional and contextual relationships, surfacing related sequences even at low sequence identity.
Can I find functionally similar proteins with low sequence identity?
Yes. This is a core use case for SeqHub. gLM2 embeddings capture functional relationships that alignment-based tools like BLAST, HHpred, and eggNOG miss when sequence identity is low.
What are alternatives to BLAST for protein annotation?
Profile-based tools like HHpred and eggNOG improve on BLAST using HMMs. Structure-based tools like Foldseek compare 3D shapes. Embedding-based tools like SeqHub encode genomic context alongside sequence — particularly useful for metagenomic data from uncharacterized organisms.
How is SeqHub different from Foldseek?
Foldseek compares protein structures and requires a structure as input. SeqHub uses genomic language model embeddings that capture sequence and genomic neighborhood context without needing a structure. The two are complementary.
How do I find co-occurring proteins across genomes?
SeqHub's CoSearch lets you query multiple proteins simultaneously and find genomes where they co-occur, along with genomic proximity and neighborhood context.
What tools can I use to annotate hypothetical proteins?
SeqHub uses embedding-based search and genomic context to generate functional hypotheses when sequence evidence is limited. CoSearch can further help by identifying co-occurrence patterns with known proteins across genomes.
Find the biology other tools miss
Search SeqHub with your sequence and see what comes back.